 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 앞서 데이터센터 내 다양한 게임 활동 로그를 활용한 고도화된 모바일 마케팅 지표를 1편과 2편에 걸쳐 소개해 드렸는데요. 오늘은 그 이후에 진행한 작업으로 게임 고객의 LTV 지표를 개선한 내용을 소개해 드리려고 합니다.

2021.10.28 Data Science
자연어처리와 HR analytics
앞서 데이터센터 내 다양한 게임 활동 로그를 활용한 고도화된 모바일 마케팅 지표를 1편과 2편에 걸쳐 소개해 드렸는데요. 오늘은 그 이후에 진행한 작업으로 게임 고객의 LTV 지표를 개선한 내용을 소개해 드리려고 합니다.
‘고객 생애 가치’를 의미하는 LTV(Life Time Value)는 특정 서비스를 이용하는 고객이 일생에 얼마만큼의 이익을 줄 것인지를 정량적으로 추정한 것으로 CLV(Customer Life time Value)라고도 합니다. 일반적으로 LTV의 개념은 다음과 같은 식으로 표현할 수 있습니다. 이자율이나 할인율 등을 고려하면 더 정확하게 계산할 수 있습니다.
= (첫해에 고객이 준 이익의 총합) − (신규 고객 유치에 들어간 비용)
+ (둘째 해에 고객이 남아 있을 확률) × {(둘째 해에 고객이 준 이익의 총합) − (고객 유지에 들어간 비용)}
+ (셋째 해에 고객이 남아 있을 확률) × {(셋째 해에 고객이 준 이익의 총합) − (고객 유지에 들어간 비용)} + ⋯
즉, LTV의 관점에서는 당장 매출을 높이는 것에 집중하는 것보다 고객 유치 비용과 고객 유지 비용을 최적으로 줄이는 것이 중요합니다. 또한 계속해서 고객의 재방문 비율이나 잔존 비율을 높게 유지하는 것이 중요합니다. 게임에서도 이와 비슷합니다. 눈앞의 단기적인 이익에 집중하기보다 유저들이 계속해서 다시 찾는 게임을 만드는 것이 LTV를 높이는 중요한 포인트가 됩니다. 따라서 고객의 LTV를 최대한 정확하게 추정하고 관리하는 것은 마케팅이나 서비스 운영 측면에서 매우 중요합니다.
저희는 예전부터 이런 LTV의 중요성을 인지하고 아래와 같은 두 가지 방식을 이용한 추정 지표를 개발해 활용하고 있습니다.
등비수열을 이용한 방식은 단위 기간당 평균 결제 금액(ARPU)과 잔존율(r)이 장기적으로 수렴한다는 가정하에 LTV를 추정하는 방식입니다. 앞서 설명한 LTV 개념에 이러한 가정을 적용해 추정식을 작성해 보면, 아래와 같이 나타낼 수 있습니다.
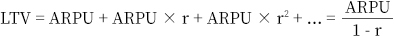
즉, 유저의 평생 가치를 구할 때 단위 기간당 평균 결제 금액을 첫째 항, 단위 기간당 리텐션을 공비로 하는 등비수열로 보고 이 수열의 무한급수를 계산하는 방식입니다. 이 방식은 직관적이고 계산하기도 쉬워 여러 분야에 널리 사용되고 있죠. 하지만 실제 게임에서 단위 기간당 평균 결제 금액과 잔존율을 살펴보면 게임 출시 초반과 후반의 차이가 크며, 단위 기간을 어떻게 설정하는지 그리고 단위 기간을 설정하는 시점이 언제인지에 따라 편차가 매우 크다는 문제가 있습니다([그림1] 참조).
[그림1] 모델 가정과 맞지 않는 자사 게임의 실제 리텐션과 ARPU 변동성
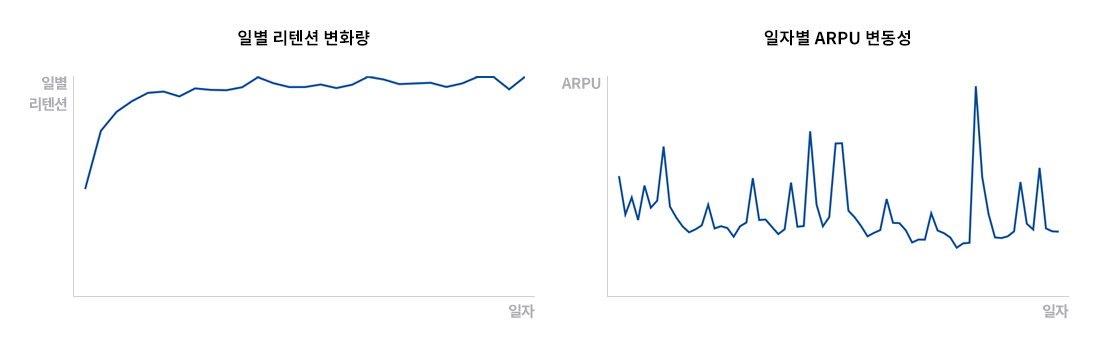
예측 모델을 이용한 방식은 유저의 여러 가지 특징을 피처로 이용해 향후 예상 매출을 예측함으로써 더 직접적으로 LTV를 추정하는 방식입니다. 저희는 유저의 플레이 활동 및 결제 관련 정보에서 크게 거래의 최근성(Recency), 빈도(Frequency), 규모(Monatary)와 관련된 속성(이런 속성들을 보통 앞 글자만 따서 ‘RFM’이라고 부름)들을 뽑아 피처로 활용했습니다. 그리고 학습 알고리즘으로 Random Forest를 이용했습니다. 이 방식은 (1)의 방식과 같은 가정이 필요 없다는 장점이 있지만, 피처 추출이나 라벨 데이터 확보가 쉽지 않아 정확한 예측 모델을 만들기 어렵습니다. 다수의 게임에서 범용적으로 사용할 수 있는 안정적인 피처를 찾기 어려울 뿐만 아니라 시간이 지남에 따라 예측 모델의 정확도가 점점 떨어지는 문제도 해결해야 하기 때문입니다. 실제 저희가 경험한 바에 따르면 초반에 높은 정확도를 보이던 예측 모델이 장기간 방치된 경우 아래와 같이 실제 매출과 매우 큰 차이를 보이는 것을 확인할 수 있었습니다.
[그림2] 정확도가 매우 떨어진 RFM 모델의 최근 예측치와 실측값
그래서 저희는 (1)의 방식과 (2)의 방식의 단점을 각각 보완하기 위해 그동안 두 가지 지표를 모두 제공하고 있었는데요. 문제는 이 두 방식의 추정치가 서로 다르다 보니 오히려 사용자에게 혼란을 준 것입니다.
기존 제공 지표의 단점을 보완하려면 정확한 하나의 지표를 만드는 것도 중요하지만 효율성을 위해 모든 게임에 공통으로 사용할 수 있는 일반적인 기법을 개발해야 했습니다. 이를 위해서는 게임별 특성을 고려해 별도의 피처나 라벨 데이터를 확보하는 방식은 적절하지 않다고 판단했죠. 따라서 가장 기본적인 데이터인 ARPU와 리텐션만으로 LTV값을 추정하되, 기존 방식보다 더 정교한 모델링 기법을 고안해야 했습니다.
ARPU나 리텐션의 변동성을 최소화하려면 측정 기간을 매우 길게 주면 됩니다. 하지만 그럴 경우 LTV 지표를 기민하게 제공할 수 없습니다. 보통 게임 운영이나 사업 쪽에서 지표를 가장 열심히 보는 시기는 게임 론칭 초반인데 이때 신속하게 제공하지 못하면 아무리 정확한 지표를 뽑아도 아무도 보지 않는 지표가 될 수 있습니다. 따라서 저희는 정확도가 다소 떨어지더라도 게임 론칭 후 최소 일주일 이내에 추정 지표가 나오는 것을 목표로 삼았습니다. 대신 시간이 지나면서 기존 추정치에 이용했던 정보와 새롭게 쌓이는 정보를 결합해 정확도를 높여 나가도록 모델링했습니다. 더 나아가 리텐션을 계산하려면 유저의 이탈 여부를 확인하는 기간도 필요하기 때문에 리텐션 대신 접속률 정보만으로 대략적인 리텐션을 추정하는 방법도 고안했습니다.
예를 들어 게임 론칭 시점이 1월 1일이라고 가정하면, 1월 1일에 접속한 유저의 7일간(1~7일) 일별 ARPU와 접속률 데이터를 이용해 1월 7일에 신속하게 지표를 추정합니다. 1월 8일 추정치에는 1월 1일에 접속한 유저의 8일간(1~8일) 정보와 1월 2일에 접속한 유저의 1월 8일까지의 7일간(2~8일)의 정보를 결합해 추정치를 보완합니다. 1월 9일 이후 추정치도 비슷한 방식으로 누적된 데이터를 활용해 점차 정확한 추정값을 얻을 수 있습니다.
이때 과거 데이터를 무한하게 누적할 경우 연산에 대한 부담이 커질 뿐 아니라 모델 자체도 너무 오래된 정보로 편향이 생길 수 있습니다. 따라서 예측의 정확성과 로직별 소요 시간을 절충함으로써 과거 수치는 학습에 사용되지 않도록 조절했습니다.
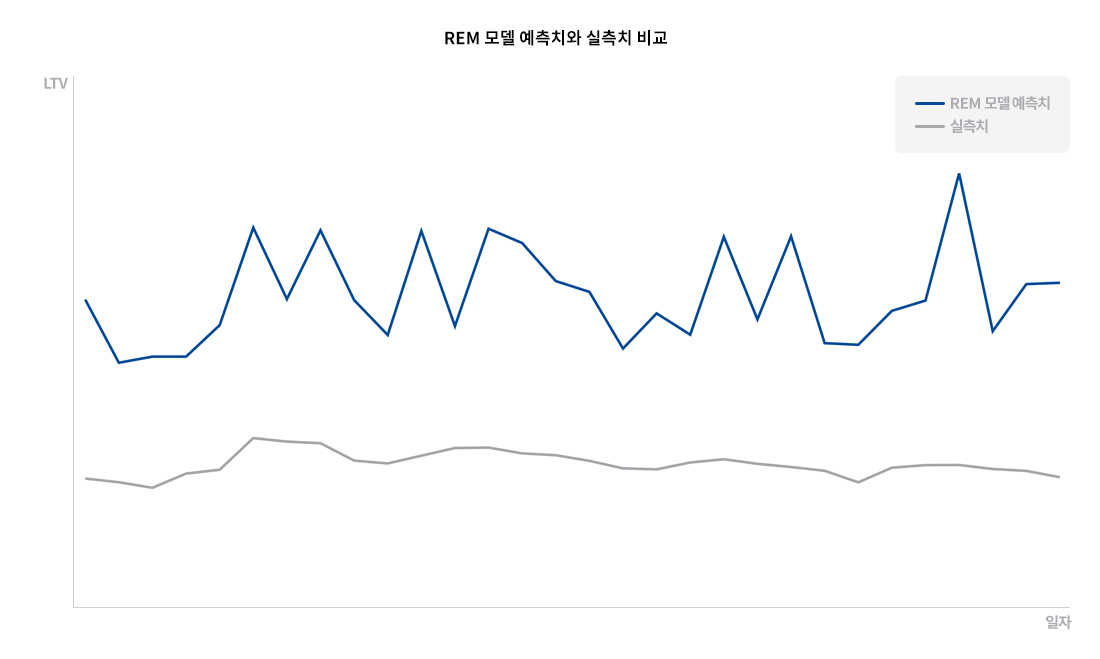
ARPU는 주말이나 방학 같은 특정 시기에 따라 편차가 크고, 대규모 프로모션 등의 이벤트에 영향을 많이 받기 때문에 특정 패턴이나 확률 분포를 가정한 모델링 방식으로는 추정하기 어려웠습니다. 그래서 (어설픈 예측 모델링을 적용하기보다) 일자별 ARPU의 이동 평균을 구함으로써 변동성을 최대한 완화하는 방법을 이용했습니다.
[그림3] 일자별 ARPU와 ARPU의 이동 평균 비교
[그림 3]과 같이 일자별 ARPU는 특정 날짜에 따라 튀는 경우가 발생하지만, 시간이 지날수록 그 변동 폭이 비교적 짧은 시간 안에 안정적으로 감소하는 것을 확인할 수 있었습니다.
조금 허무할 정도로 간단한 방법이긴 하지만 어설프게 정교한 기법을 적용한다면 얻는 성능상의 이익보다 이후 관리하는 데 드는 비용이 오히려 더 클 것으로 판단했습니다.
리텐션을 구하려면 먼저 유저의 이탈 여부를 판단하는 것이 필요합니다. 그런데 유저마다 게임에 접속하는 패턴이 다르고, 개인적인 사정에 따라 하루 정도 접속을 안 할 수도 있기 때문에 단순히 어제 접속한 유저가 오늘 접속하지 않았다고 해서 이탈한 것으로 판단할 수는 없습니다. 따라서 어떤 유저가 게임에서 정말 이탈했는지를 판단하기 위해서는 장기간에 걸쳐 유저의 접속 여부를 확인한 후 충분히 긴 기간 접속하지 않았을 때 이탈이라고 판단해야 합니다. 하지만 이렇게 되면 이탈 여부를 판단하는 것 자체에 너무 많은 시간과 리소스가 필요합니다. 정확하게 추정하는 것도 중요하지만 앞서 분석 목표에서 언급했듯이 저희의 목표는 최대한 지표를 기민하게 제공하는 것이기에 이탈 여부를 정확히 판단하지 않고서도 잔존율을 추정하는 방법이 필요했습니다.
그래서 리텐션 측정 시 별도의 이탈 여부를 판단하지 않고 유저들의 접속률을 이용해 추정하는 방식을 사용했습니다. 예를 들어, 1월 1일(기준일)에 접속한 유저가 100명이라면 기준일에 접속한 100명 중 1월 2일에 접속한 유저는 50명, 또 기준일에 접속한 100명 중 1월 3일에 접속한 유저는 55명 등으로 접속률을 과 같이 구할 수 있습니다.
이렇게 접속률을 추적하면 일자별로 수치가 오르내리기를 반복하다가 결국에는 서서히 감소하는 형태로 그래프가 그려집니다. 따라서 이 값을 이용해 대략적인 잔존율 그래프를 적합할 수 있습니다. 여기서 좀 더 정확한 추정을 위해 접속률이 전날보다 상승한 경우에는 이전 시점까지의 접속률 중 최솟값으로 대체하도록 전처리 작업을 추가했습니다. [그림 4]를 보면 이렇게 전처리 작업을 했을 때 추정의 정확도가 좀 더 높아지는 것을 확인할 수 있습니다.
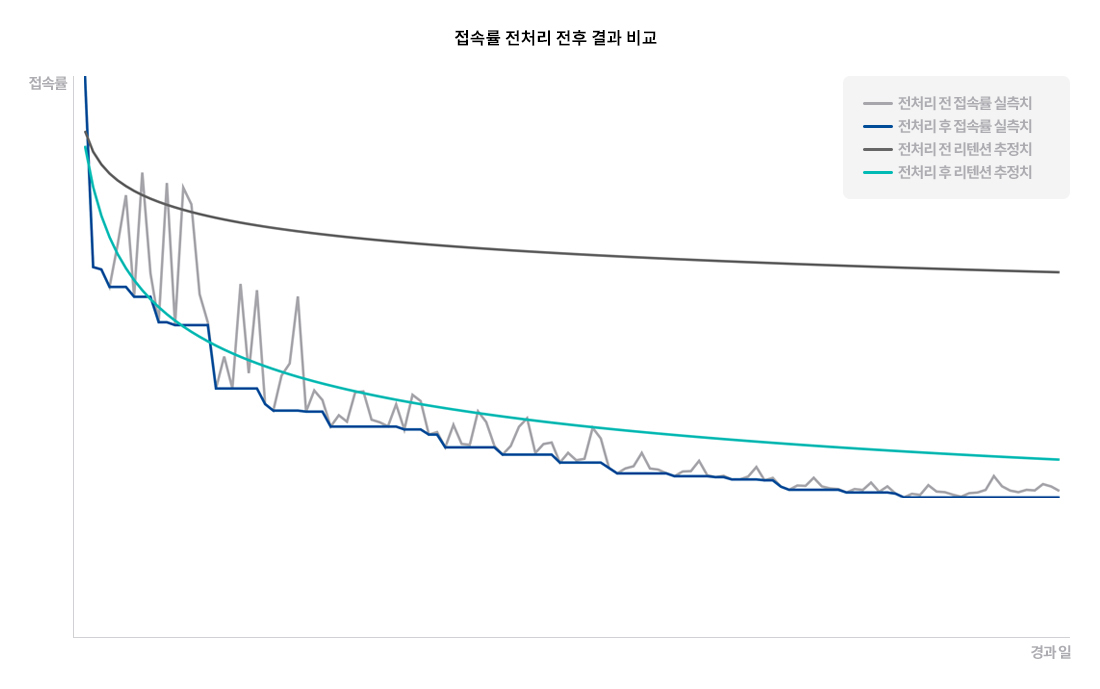
[그림4] 특정 날짜의 접속률 데이터 전처리 전후 모델링 결과 비교. 이처럼 접속률 변동이 유독 큰 날의 데이터를 전처리 작업 없이 그냥 사용하면 추정의 정확성이 매우 떨어집니다.
리텐션을 추정할 때는 유리 함수를 적합하는 방법과 sBG(shifted Beta Geometric) 모델링을 조합해 사용했습니다.
먼저, 유리 함수 적합은 유저의 리텐션 그래프를 형태라고 가정하고 이 함수의 파라미터인 a, b, c, d를 구하는 방법을 말합니다. 이때 이 파라미터들은 비선형 최소 제곱법 방식을 이용해 구했습니다. 비선형 최소 제곱법 방식은 tt에 따라 비선형 함수 피팅값(미리 정의한 분수 함수 개형의 함숫값)과 실측값(자사 리텐션 데이터)의 잔차 제곱 합이 최소가 되도록 하는 최적의 파라미터를 구하는 알고리즘입니다.
이 방법은 비교적 단순하다는 장점이 있지만 리텐션에 대한 함수 형태가 이럴 것이라는 가정이 맞지 않으면 적합도가 떨어진다는 단점이 있습니다. 따라서 이를 보완하기 위해 함수의 형태를 정하지 않는 대신 확률 분포를 이용해 잔존율을 모델링하는 sBG 모델 방식을 사용했습니다. sBG 모델은 유저의 이탈 확률이 베타 분포를 따르는 것으로 가정하고, t 시점의 이탈 확률과 생존 확률을 계산해 리텐션 함수를 모델링하는 알고리즘입니다. (sBG 알고리즘에 관한 자세한 내용은 Appendix를 참고하시기 바랍니다.) 물론 sBG 역시 확률 분포를 가정하고 있기에 이 가정이 맞지 않으면 적합도가 떨어집니다.
저희가 테스트해 본 바에 따르면 유리 함수는 under-estimating이 되는 경향이 있으며, sBG 모델은 over-estimating이 되는 경향이 있었습니다. 따라서 양쪽의 단점을 보완하기 위해 두 방법을 모두 사용해 각각 적합한 후 이들의 평균을 이용해 최종적인 리텐션 추정치를 구했습니다.
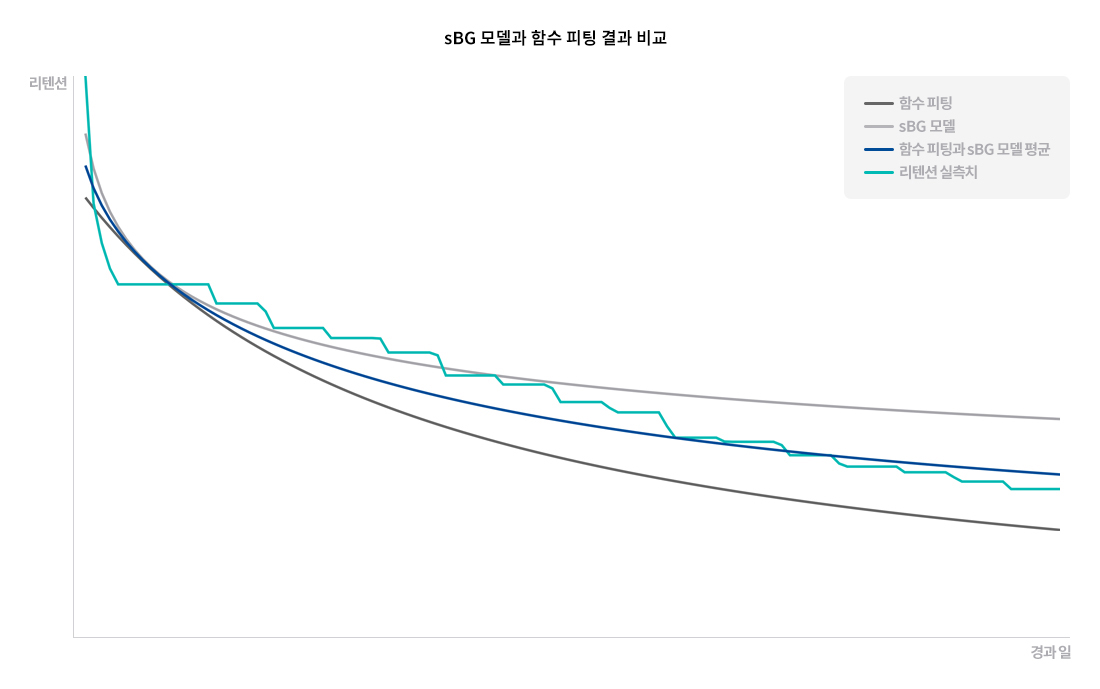
[그림5] 초반 데이터로 리텐션을 추정해 후반 리텐션이 잘 적합되었는지 살펴보면 함수 피팅 방식은 under-estimating이 되는 경향이 있고, sBG 모델 방식은 over-estimating이 되는 경향이 있어 두 방식의 평균을 사용했습니다.
위에서 추정된 리텐션과 ARPU를 이용해 LTV를 구하면 다음과 같이 계산할 수 있습니다. (아래 식에서 ‘R(t)’는 시간에 따른 잔존율 함수를 의미합니다.)
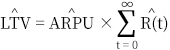
그런데 고객의 평생 가치를 측정하기 위해 ‘t=∞’까지 리텐션을 구할 경우, 현재 추정되는 잔존율 곡선은 시간이 지날수록 완만해지기 때문에 LTV가 지나치게 높게 추정되는 문제가 발생합니다. 게다가 애초에 수십 년의 고객 가치를 추정하는 것 자체가 운영이나 사업적인 목적에서 그렇게 중요하지 않습니다. 따라서 고객 관리나 지표 모니터링 측면에서 좀 더 유용하다고 판단되는 월, 분기, 반기, 년 단위의 기간별 LTV를 계산해 지표로 제공하기로 했습니다(그래서 지표의 명칭도 LTV 대신 ‘고객당 예상 수익’이라고 변경했습니다). 또한 단순히 하나의 값으로 예상 수익을 추정하기보다 리텐션과 매출의 표준 오차를 활용해 99% 수준의 신뢰구간을 계산해 함께 제공했습니다. (신뢰구간을 구하는 방법은 Appendix를 참고하시기 바랍니다.)
이렇게 개발한 예상 수익 추정치의 예측 성능을 확인하기 위해 추정 이후 실제 집계된 매출과 비교해 보았습니다. 이때 기존 LTV 지표와 성능 비교도 같이 진행했습니다. 각기 다른 방식으로 계산된 추정치인 만큼 각 추정치를 180일 기간에 맞게 보정한 후 MAPE(Mean Absolute Percentage Error, )를 계산했습니다. [그림 7]은 이렇게 예측 기준을 통일한 후의 비교 결과입니다. 기존 지표 중 가장 좋은 값과 비교해도 오차율이 50%에서 18%로 대폭 감소했습니다. 결과적으로 기존보다 예측 성능이 두 배 이상 향상된 것이죠. 게다가 기존 지표들은 추정치를 계산하기 위해 최대 한 달 간의 집계 데이터가 필요했던 반면, 새로 개발한 지표는 그 기간을 일주일로 단축했습니다. 더 나아가 별도의 모델 업데이트 없이도 시간이 지남에 따라 추정치가 실측치에 더 가깝게 수렴하는 장점도 있었습니다.
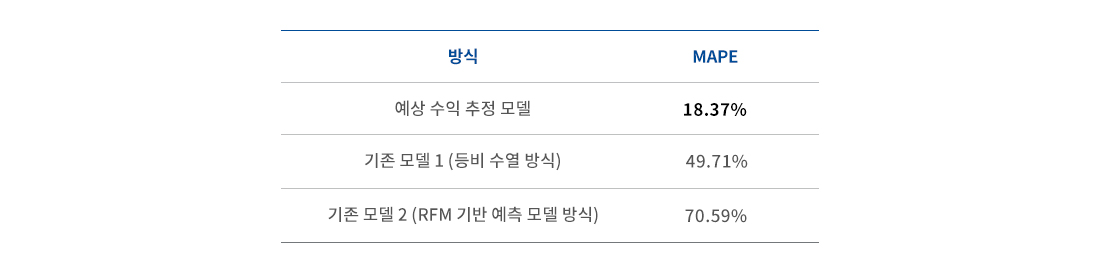
[그림6] 개선된 방식과 기존 방식의 MAPE 비교
저희가 모델링하는 대상은 전체 유저의 평균적인 생애 가치인데요. 실제로는 각 유저마다 그 가치가 매우 다릅니다. 가령, 우연히 게임을 다운로드해 하루 동안 플레이해 본 후 접속하지 않는 유저일 수도 있고, 오랜 기간 다양한 콘텐츠를 즐기는 유저일 수도 있죠. 이러한 편차를 줄이기 위해 비슷한 성향의 유저군을 세그먼테이션한 후에 각 세그먼트별로 가치를 측정해 보면 지표에 대한 신뢰도를 좀 더 높일 수 있을 것입니다. 더 나아가 이렇게 세그먼트별로 가치를 추정하면 좀 더 정교한 고객 관리와 마케팅이 가능합니다. 따라서 저희는 전체 유저의 접속 OS, 광고 매체 유입 여부, 에뮬레이터 사용 여부 등의 정보를 활용해 세그먼트를 나눈 후 세그먼트별 추정치를 계산해 더 활용성 높은 정보를 전달하게 했습니다.
이번 포스팅에서는 LTV 지표 개선 작업에 관한 내용을 공유해 드렸습니다. 최소 7일간의 접속률과 결제 정보만을 이용해 최대한 신속하게 지표를 제공하고, 이후 시간이 지남에 따라 누적된 데이터를 활용해 더욱더 정확한 추정치를 만드는 과정을 소개해 드렸습니다. 이렇게 새로 개발한 방법은 활용하는 정보에서 일반적으로 많이 사용하는 무한 등비급수를 이용하는 방식과 거의 차이가 없지만 훨씬 더 정확한(MAPE 기준 50%→18%) 추정값을 갖습니다. 더불어 유저 세그먼트별 정보와 기간에 따른 단기•중기•장기 예상 수익 비교를 통해 좀 더 활용성 높은 정보를 전달합니다!
이후에는 접속 유저의 예상 수익 지표를 바탕으로 1년간 발생한 총 매출을 추정하고 이와 관련한 보조 지표들을 개발해 신뢰도 높은 지표로 고도화시킬 예정입니다. 이 외에도 유저들의 기대 수명, 복귀 예상 고객 예측 등 정교한 고객 관리와 마케팅에 도움이 될 다양한 분석을 진행하고자 합니다. 이를 통해 조금이나마 활용성 높은 지표 생성에 기여할 수 있기를 바라며 이만 글을 마칩니다.
sBG 모델은 기하•베타 분포를 이용해 리텐션을 모델링하는 방식입니다. 유저의 이탈 확률이 베타 분포를 따르는 것으로 가정하고, t 시점의 이탈 확률과 생존 확률을 계산해 리텐션 함수를 모델링하는 것입니다. 세부 내용은 아래와 같습니다.
가정
sBG 모델에는 아래와 같은 세 가지 가정이 필요합니다.
Θ: 유저의 이탈 확률, T=1 : (초기 시점이라고 할 때)
• t시점에서 유저의 이탈 확률:
• t시점에서 유저의 생존 확률:
• 유저의 이탈 확률Θ는 베타 분포를 따름:
모델 설명
• 유저의 이탈 확률Θ가 베타 분포를 따른다는 가정을 이용해 t 시점에서 유저의
이탈 확률과 생존 확률을 추정합니다.
• Θ가 베타 분포를 따른다는 가정을 이용하면t 시점의 유저 이탈 확률과 생존
확률을 다음과 같이 나타낼 수 있습니다.
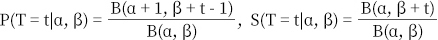
• t 시점의 유저 생존 확률을 이용하면t 시점의 유저 잔존 확률 r(t)r(t)는 다음과
같이 정의됩니다. 잔존 확률은 유저의 생존 확률 계산에 사용합니다.
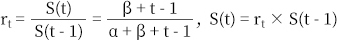
• 이때α, β는 MLE를 사용해 추정합니다.
• 추정된 을 이용하여 유저의 모든 시점의 생존 확률을 계산해 리텐션 함수로
사용합니다.
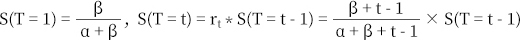
중간에 생략된 수식 전개나 자세한 설명은HOW TO PROJECT CUSTOMER RETENTION을 참고하시기 바랍니다.
ARPU의 표준 오차와 리텐션의 표준 오차를 구해 신뢰구간을 계산합니다. 표준 오차 계산에 사용된 데이터 개수를nn이라고 하면 각각의 표준 오차를 아래와 같이 구할 수 있습니다.
• 리텐션 함수는 sBG 모델 함수인 s(t)와 함수 피팅 방식으로 피팅된 분수
함수인 c(t)의 평균값입니다. 각각 독립되었다고 가정하면 아래와 같이 계산할
수 있습니다.
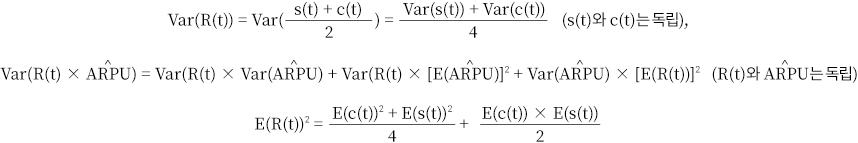
따라서 최종 신뢰구간은 아래와 같습니다.
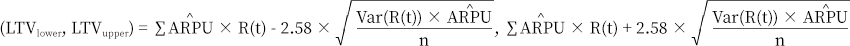

NCSOFT DANBI BLOG
RELATED