게임 속 시장은 어떻게 움직일까?
게임은 또 다른 사회이자 하나의 경제 시스템이다. 이 가상의 세계에서 무심코 하는 모든 행동이 모여 사회를 구성하고 시스템을 작동시킨다. 수많은 유저가 캐릭터를 생성함으로써 인구를 늘려 나가고, 다양한 콘텐츠 이용으로 화폐를 획득함으로써 소득을 창출하며, 필요한 아이템을 구매함으로써 소비 활동을 한다. 아래 예시를 보자.
유저 A는 몬스터를 사냥하다 좋은 아이템을 얻었다. 하지만 그 아이템은 A에게 필요한 것이 아니었기에 거래를 통해 다른 유저에게 게임 내 화폐를 받고 팔았다. 그 과정에서 A는 판매 수수료와 세금도 일부 지불했다. 그리고 아이템을 팔아 얻은 수입으로 A가 평소에 갖고 싶던 아이템을 구매했다.
위 예시처럼 게임 내에서 재화의 이동은 매우 흔한 일이며, 거래는 게임 내 재화 이동의 수단이기 때문에 이에 대한 현황을 잘 파악하는 것은 게임 전반의 설계와 운영에 중요하다. 가령 아래의 질문들에 대한 답을 찾는 데 결정적인 인사이트를 얻을 수도 있을 것이다.
경제는 게임 론칭 후 시간이 지날수록 활발해질까? 침체될까? 아니면 특정한 이벤트를 할 때에만 활성화될까?
거래는 동일 서버 내에서만 가능한데, 어느 서버에서 가장 활발할까?
위 질문들에 대해 간단하게 답할 수 있도록 거래 경제 상황을 한눈에 볼 수 있는 지표를 만들 수는 없을까? 그렇다면 거래 활성도를 파악하기 위해서는 어떤 정보를 관찰해야 할까? 거래 경제 현황을 파악하는 기준으로는 거래 규모, 횟수, 참여자 수, 거래 아이템의 가치 등 여러 가지를 손꼽을 수 있을 것이다. 하지만 모든 정보를 보기에는 시간이 오래 걸리기도 하고, 무엇보다도 너무 복잡하다. 그래서 시간의 흐름에 따른 추이를 살펴보거나 간편하게 여러 서버를 비교할 수 있도록 단 하나의 거래 시장 종합 지표를 만들어 보기로 했다.
한눈에 보여줘
많은 것을 한눈에 보기 위해서는 정보를 압축해야 한다. 사진이나 음악도 압축하게 되면 화질과 음질을 어느 정도 포기해야 하지만, 그 대신 이동은 훨씬 자유로워진다. 데이터도 마찬가지이다. 방대한 양의 데이터를 하나의 지표로 압축하면 세부 정보는 손실되지만 사용성은 훨씬 증대된다. 선택과 집중을 위해 목표로 하는 지표가 지녀야 하는 특성을 아래와 같이 정리했다.
수치가 크면 클수록 호황을 의미했으면 좋겠다.
거래 규모가 크고, 참여자가 많으며, 거래가 빈번하고, 고가 아이템의 거래가 활발할수록 호황을 의미했으면 좋겠다.
수치 자체에 상한선을 두지는 않되, 음의 값은 없으면 좋겠고, 시간에 따른 비교나 서버 간의 비교가 쉬운 형태였으면 좋겠다.
정리를 하다 보니 접근 방식이 떠오르기 시작했다. 지난 포스팅 중 모바일 마케팅 분석 무작정 따라하기 #2 라는 글이 있는데, 이 분석에서는 종합 광고 성과 지표 개발을 위해 주성분 분석(PCA: Principal Component Analysis)을 사용했다. 변동성을 가장 잘 설명하는 주성분만 일부 추출하여 각 주성분이 갖는 설명력에 가중치를 곱해 합산한 것이다. 이 방식과 유사하게 거래 호황 정도를 나타내는 종합 지표를 산출하기로 했다. 종합 광고 지수와 마찬가지로 거래 종합 지수 또한 거래 규모나 빈도 등 종합 지수에 반영하려는 값이 크면 클수록 호황을 나타내고자 하기 때문에, 앞선 글과 동일하게 주성분 계수의 값이 음수가 되지 않도록 Non-Negative Sparse PCA를 사용하였다. 이와 관련한 상세 설명은 해당 포스팅을 참고하길 바란다.
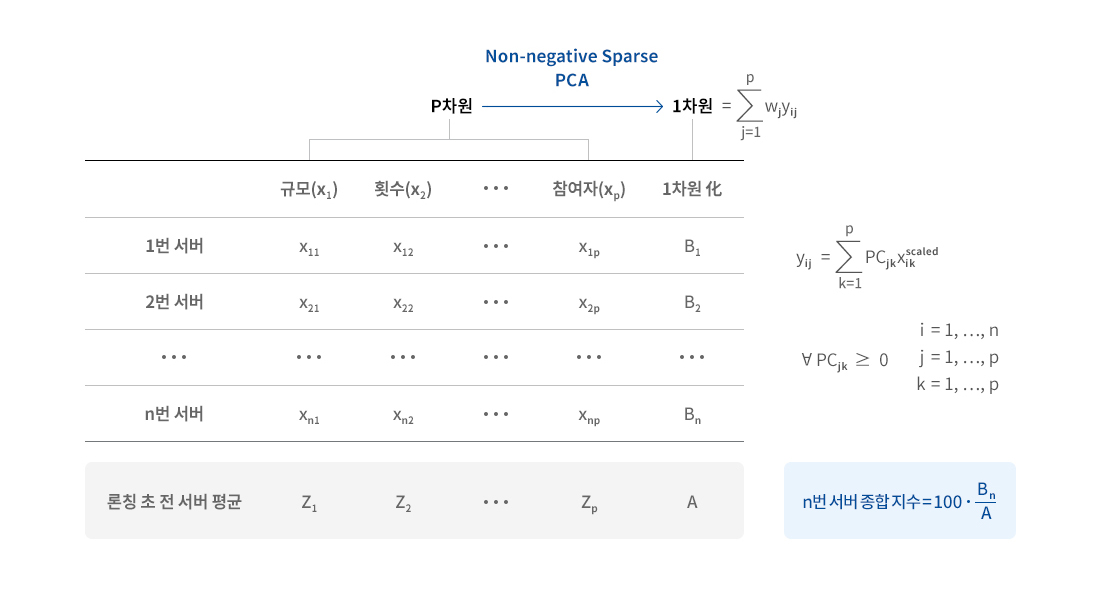
거래 종합 지수의 산출 방법을 간단히 도식화하면 위 [그림 1]과 같다. 이때, 시간의 흐름에 따른 변화를 관찰하는 방법 중 하나는 게임 론칭 후부터 현재까지 모든 기간에 대한 서버별 데이터를 한꺼번에 사용하여 주성분 분석을 하는 것이다. 그러면 서버에 따른 비교는 물론이고 론칭 초부터 현재까지 시간에 따른 비교가 가능해진다. 그러나 이 방법을 사용하면 시간이 흘러 새로운 데이터가 축적되었을 때, 최근 데이터를 포함한 전체 데이터를 다시 분석해야 하는 번거로움이 생긴다. 더군다나 동일한 시점의 데이터일지라도 분석에 사용한 데이터의 기간이 늘어나기 때문에 전체 데이터의 분포가 달라져 계산된 최종 수치가 바뀌게 된다. 예를 들어, 론칭 초부터 어제까지의 데이터로 분석했을 때 어제의 종합 지표는 300이었는데, 론칭 초부터 오늘까지의 데이터로 분석하면 어제의 데이터 자체에는 변화가 없음에도 불구하고 오늘의 데이터가 추가되면서 전체 데이터의 분포가 바뀌어 어제의 종합 지표가 310으로 달라질 수도 있다는 것이다.
이러한 상황을 피하고자 데이터가 누적되어도 수치가 바뀌지 않으면서 시간에 따른 추이의 관찰이 용이한 지표를 만들기 위해 기준점을 정하기로 했다. 먼저 앞선 예시처럼 론칭 초부터 축적된 데이터 전부를 사용해 한꺼번에 주성분 분석을 하지 않고, 새로 데이터가 쌓일 때마다 새로운 데이터만 사용하여 주성분 분석을 시행한다. 그러면 다른 기간에 해당하는 데이터끼리는 따로 분석이 되기 때문에 분석 시 고려된 데이터의 분포가 각각 다를 것이다. 당연히 이대로는 시간의 흐름에 따른 비교가 불가능하다. 하지만 론칭 초의 값을 기준으로 두고, 이 값에 비해 얼마나 변화했는지 보는 방식을 채택하면 비교가 가능하다. 기준 시점의 시가총액의 합을 100으로 두고 현재의 시가총액이 얼마인지 나타냄으로써 금융 시장의 호황도를 살펴보는 KOSPI에서 아이디어를 얻어, 론칭 초 전 서버의 평균적인 상태를 기준 지수 100으로 정했다. 그리고 데이터가 쌓일 때마다 최신 데이터만을 분석해 기준 지수와 규모가 맞도록 조정해 서버나 시간에 따른 비교가 편리하도록 했다.

[그림 2] 시간의 흐름에 따른 변화를 관찰하는 두 가지 방법
하루 단위로 거래 종합 지수를 산출한다고 하자. 먼저 론칭 첫날의 각 서버별 데이터를 사용해 주성분 분석을 하고, 로테이션된 각 변수에 주성분의 분산 기여도를 가중치로 두고 합산해 서버별로 1차원 축소 값을 만든다. 이렇게 계산된 i번 서버의 1차원 축소 값을 Bi라고 하자. 그리고 원 데이터의 모든 피처 값이 론칭 첫날의 전 서버 평균치를 갖는 가상의 서버가 있다고 가정한 다음, 동일한 방식으로 이 가상의 서버에 대한 1차원 축소 값을 구한다. 이를 A라고 하자. 이제 Bi에 100을 곱하고 A로 나누면 종합 지수가 된다. 다음 날이 되었을 때도 마찬가지다. 그날의 데이터들로만 주성분 분석을 해 동일한 방법으로 각 서버별 1차원 축소 값 Bi들을 계산한다. 그 다음, Bi에 100을 곱하고 A로 나누면 이날의 i번 서버 종합 지수가 된다. 이 거래 종합 지수는 론칭 첫날의 전 서버 평균적인 상태를 100이라 할 때, 이날의 해당 서버 거래 활성도를 의미한다. (Bi=A일 경우, 거래 종합 지수는 100이 된다.) 예를 들어 1번 서버의 종합 지수가 105라는 것은 론칭 첫날의 전 서버 평균 대비 105%의 활성도를 갖는다는 것을 의미하고, 2번 서버의 종합 지수가 108이라면 1번 서버보다 2번 서버의 거래가 더욱 활발함을 나타낸다. 수많은 정보가 하나의 숫자로 압축된 것이다.
실제 데이터 들여다보기
이렇게 개발한 거래 종합 지수로 서버에 따른 활성도 차이나 시간에 따른 추이를 살펴보기 위하여 아래 [그림 4]와 같이 전체 서버의 종합 지수 변화 차트를 그려보았다. 녹색 선은 종합 지수의 전 서버 평균선을, 사각형의 범위는 각 서버별 종합 지수의 Q1에서 Q3를, 세로선은 최솟값부터 최댓값까지를 의미한다.
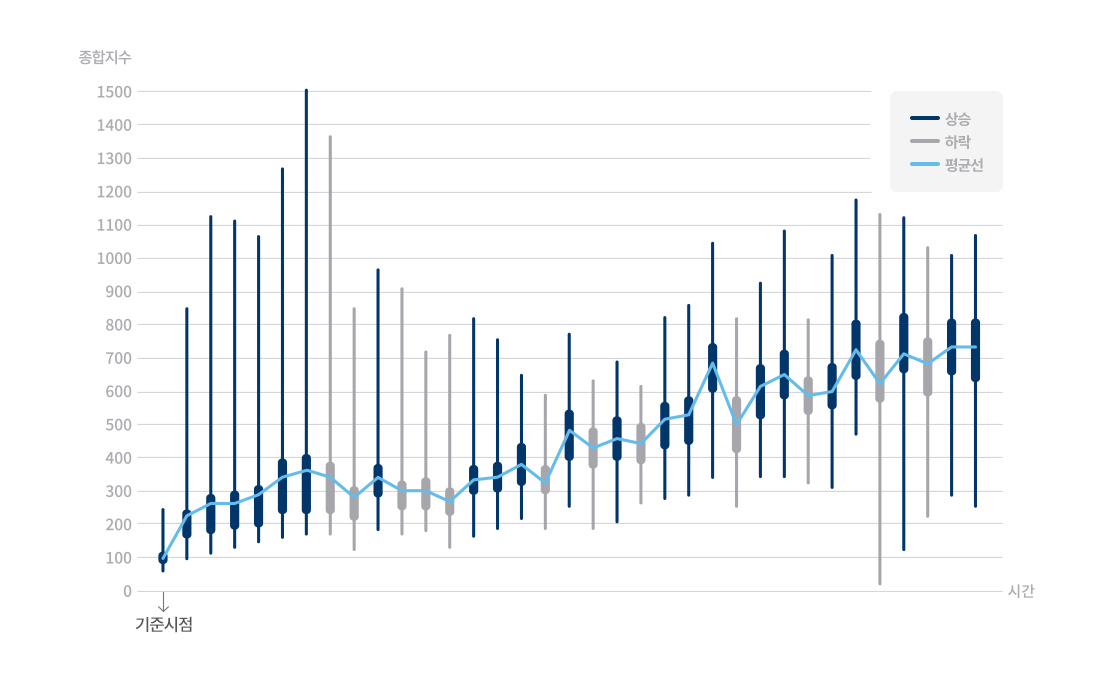
[그림 4] 시간에 따른 거래 종합 지수 그래프
위 [그림 4]를 보면 일부 기간 등락이 관찰되고 서버 간 편차가 비교적 심한 기간도 존재하지만, 시간이 흐름에 따라 전체적으로 점차 수치가 증가해 마지막에는 약 800에 달하는 것을 확인할 수 있다. 이는 시간이 지날수록 전반적으로 거래가 활발해지며 기준 시점 대비 마지막 시점에 활성도가 약 8배에 달한다는 것을 의미한다. 그런데 이 거래 종합 지수를 보니 전체 거래 상황에 대한 종합 지수뿐만 아니라 고가 아이템의 거래에 대한 활성도가 추가로 궁금해졌다. 그래서 마치 KOSPI 200이 코스피를 대표하는 종목 200개에 대한 지수인 것처럼, 전체 거래 중에서 고가 아이템에 한정한 지수를 구해보기로 했다.
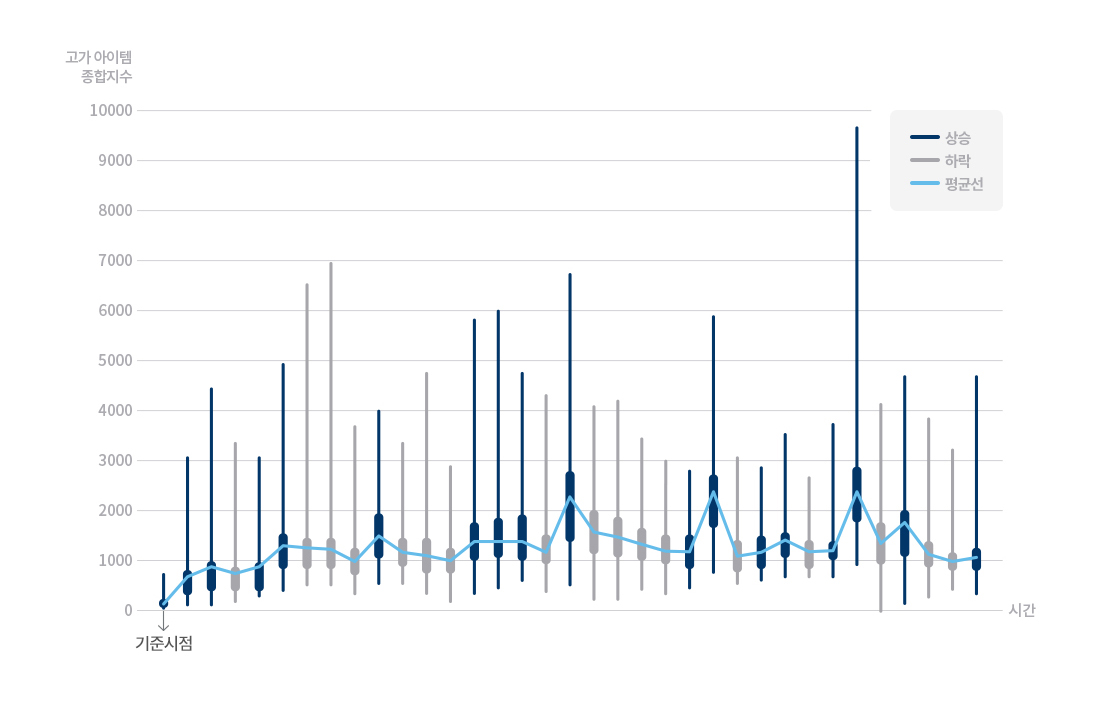
[그림 5] 시간에 따른 고가 아이템 거래 종합 지수 그래프
고가 아이템에 한정한 데이터를 가지고 결과를 동일한 방식으로 그려보니 꽤나 흥미로운 사실을 관찰할 수 있었다. 위 [그림 5]에서 보다시피 고가 아이템 거래 종합 지수는 특정 기간에만 뛰는 양상이 나타났는데, 공교롭게도 지수가 급등한 날들은 특정 이벤트가 있었던 기간이었다. 고가 아이템의 거래를 활성화하는 것이 해당 이벤트의 기획 의도였다면 성공적인 결과를 얻었다고 할 수 있다. 설령 이러한 결과를 예상치 못했다 하더라도 향후 고가 아이템의 거래를 활성화하고자 하는 시기에 해당 이벤트를 다시 고려해 볼 수도 있을 것이다. 물론 다른 자료들을 통해서도 충분히 동일한 사실을 추론해 낼 수 있지만, 단 하나의 숫자가 시장의 전반적인 상황을 나타내는 대표성을 지닌다는 것이 거래 종합 지수가 지닌 큰 장점이 아닐까 싶다. 한편 이러한 거래 종합 지수는 종종 다른 자료들과 연관 지어 관찰될 때 새로운 인사이트를 주곤 한다. 종합 지표 및 관련 자료들을 보다 효과적으로 전달하기 위한 활용 방안은 < R Markdown을 활용한 Interactive Report 만들기> 포스팅에 자세히 나와있으니, 관심있는 분들은 이곳에서 확인하길 바란다.
NCSOFT DANBI BLOG
Data Analytics aNd Business Insights.
엔씨에 존재하는 다양한 데이터에 대한
분석을 통해 인사이트를 찾고
기계학습 및 통계 모델링을 이용해
고도화된 지표 및 시스템을 개발합니다.
엔씨의 살아있는 데이터 이야기,
DANBI BLOG 바로 가기
Data Analytics aNd Business Insights.
엔씨에 존재하는 다양한 데이터에 대한
분석을 통해 인사이트를 찾고
기계학습 및 통계 모델링을 이용해
고도화된 지표 및 시스템을 개발합니다.
엔씨의 살아있는 데이터 이야기,
DANBI BLOG 바로 가기
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL